Background
Recently I had the opportunity to design and build a new general purpose redis connector mechanism for managing the connections between my backend processes and our redis elasticache fleet. The impotus for this change had to do with poor response times, a heavy usage of a single replica while another was sitting unused, and a pending requirement to use TLS and at-rest encryption when communicating with our redis clusters.
AWS Topology
The premise of my topology design, is keep the data as close to processes as possible. Not really a new concept, but one is sometimes forgotten in the cloud; especially knowing just how impressive AWS’s networking actually is. While they do offer extremely fast networking between their availability zones it’s still not as fast as staying in the same availability zone.

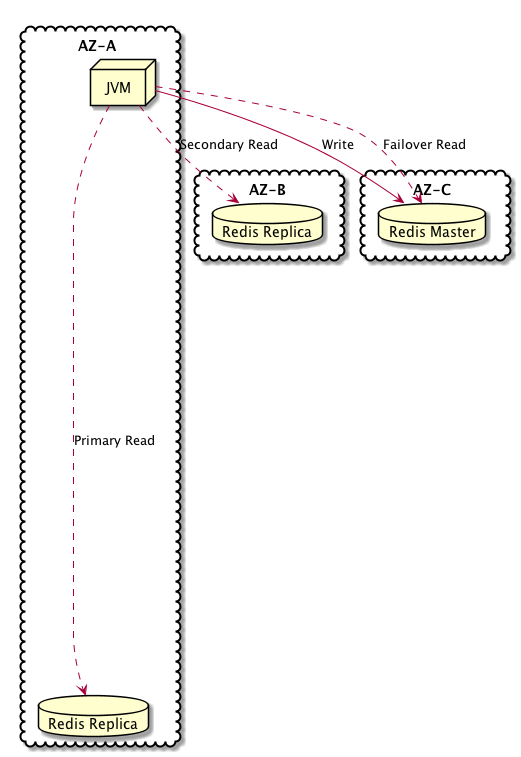
The application for which I designed this, is presently deployed in 2 availability zones in a region that offers (at the time of writing) 5 availability zones. We keep our middleware processes in AZ-A and AZ-B, we also keep a non-sharded redis cluster in which we have AZ-C hold the master, AZ-A has a replica and AZ-B has a second replica. All of our long running applications (those that serve our HTTP requests) run from AZ-A and AZ-B; lambdas will actually operate from all three of the above mentioned availability zones but those are used for async processing not serving traffic as quickly as possible.
The goal of this topology, is that a process operating from AZ-A will perform cache reads from the replica in AZ-A under normal circumstances, same holds true for a process that is running on AZ-B.
Connector Designs
How we go about achieving that outcome, is where the programming magic comes in play. The component that I designed around this approach, operates by opening 4 connections and then performing operations it has been instructed to perform against the best of those connections.
Master connection
The first connection is a to the master endpoint; which is a DNS with very low TTL (or if encryption is enabled, a separate process that manages encrypting values using KMS prior to write into the redis cluster) that will also point to the current redis master node. Upon failure, it will be updated to point at the node which won the master election and went from being a replica to being the master.
The component uses this connection for two purposes. The first purpose is that of performing writes into the cache cluster. The second purpose this connection is as a fall-back in the event that a communications failure when performing a read against the replicas. That fallback works very well because elasticache is very good at detecting when the master node fails and performing automated recovery that promotes a replica (or brings up a new if necessary) and updating the master DNS entry which has a very low TTL.
Replica connections
A connection to each of the redis nodes is established, in this case there are 3 nodes and we open a connection to each of them which is treated as though it were read-only.
These connections monitored by a background-thread which will periodically check which connection is actually to the master node and which node is responding fastest.
The technique being used is that every 5 seconds each connection is checked for status, when a connection fails to respond; it is assumed to be down and will not be used for processing read commands. The first stage of the check is to determine if the connection to the master or a replica, that is determined by performing an INFO request. For the replica connections, a sequence of 3 ping commands is sent and the response time is monitored; then those response times are averaged and the connections are ranked for read usage accordingly.
Operation execution patterns
This technique while simple in concept, was actually somewhat difficult to correctly implement; thankfully the lettuce client made this a much simpler by facilitating most of the low-level aspects with great resiliency. By leveraging a connection to the master which guarantees “at-least-once” execution of a command, and replicas configured for “at-most-once” execution; this connector is able to quickly skip offline replicas and switch to the master.
The combination allowed that read commands which are critical to execute, but can tolerate a delay for reconnection are able to attempt the read command against each replica connection in order, then if those are exhausted perform the read against the master connection.
While individual read operations that can tolerate a read failure and treat connectity issues like a miss, are able to be executes against only the replicas which immediately returns with a failure exception when the connection is down, though we actually have it attempt against each replica connection before returning the miss response.
Write operations are required to be routed to the master node, which is using a at-least-once mode of operation that will block until the write has been completed. For the purposes of the application I’m working with that isn’t a problem. Though to be fair, in order to allow our appliation to respond as quickly as possible we take advantage of multiple threads and have the fill operation after a miss issue the write in a separate thread from the one that served the response to the caller.
SSL Implications
This part of the story is a bit interesting, as it actually will showcase a limitation of the lettuce client. Within lettuce, there are a number of connection options for a long time I had been using the MasterSlave type connection.
What I found was that when I tried to connect over TLS, it just wouldn’t attempt. After doing some digging, I discovered that it has to do with how it attempts to determine master vs replica; and that with the host obviscation that elasticache does and TLS exaserpating that obfiscation; this connection type just wouldn’t try; and to be fair that actually is documented in the lettuce wiki.
While experimenting, I found that a normal connection over TLS had no issues and worked quite well. As I already had a configuration model that identified the master and all the nodes seperate from one another; I choose to implement this component that took over the topology understanding from lettuce and used bunch of independent connections for routing and background monitoring for keep-alive and topology updates.
In the end, I ended up with a component that actually worked quite a bit better than the original managed connection because I support topology updates either from network weather and from node failures and failovers of the master node. An event type which would likely have required terminating and re-creating the MasterSlave connection.
Results
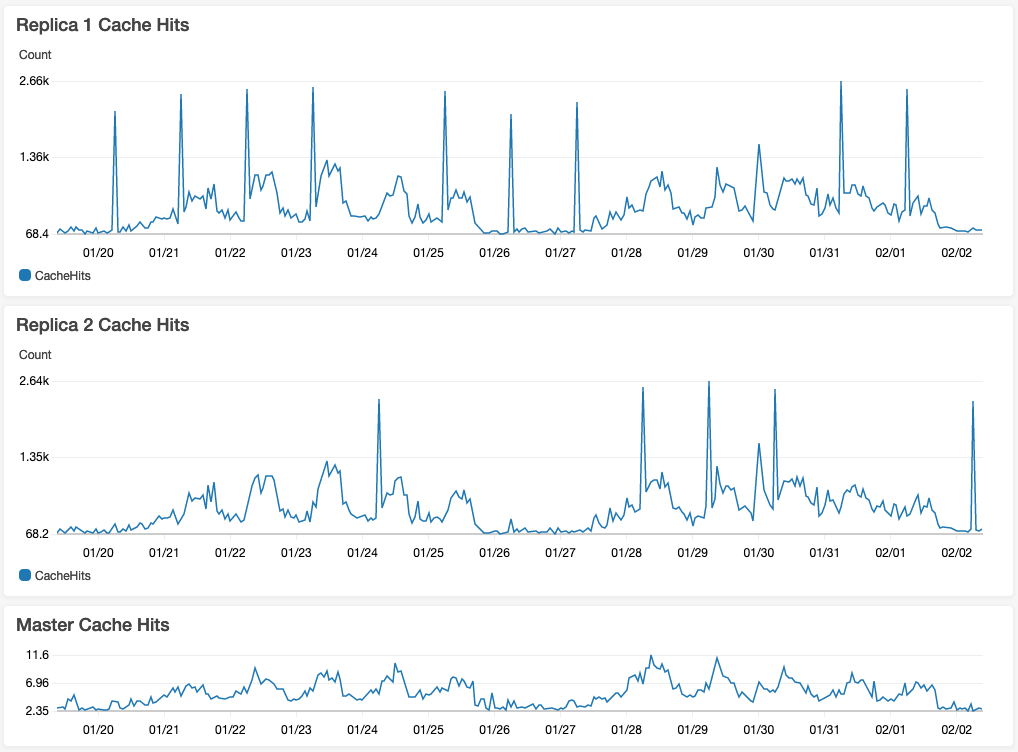
This has worked remarkably well in terms of keeping the reads within the availability zone. This also reduced the average response time of our application by half once all session management and cache responsibilities were routed through this component.
I’ve included a cloudwatch dashboard view of my redis hit stats across the three nodes for the past two weeks. While the usage stats are pretty low for what redis can handle, it still deponstrates how this type of connection routing can affect your load distribution.
References
Lettuce Client: https://lettuce.io/
- Lettuce wiki
- Lettuce command execution reliability, covers the at-most-once vs at-least-once concept
- MasterSlave connection javadoc
AWS ElastiCache: https://aws.amazon.com/elasticache/redis/